社内技術勉強会 資料 2022年9月29日 19:00~20:00
作成者 Aoki Yuichiro
作成日 2022/9/29
更新日 2022/9/29

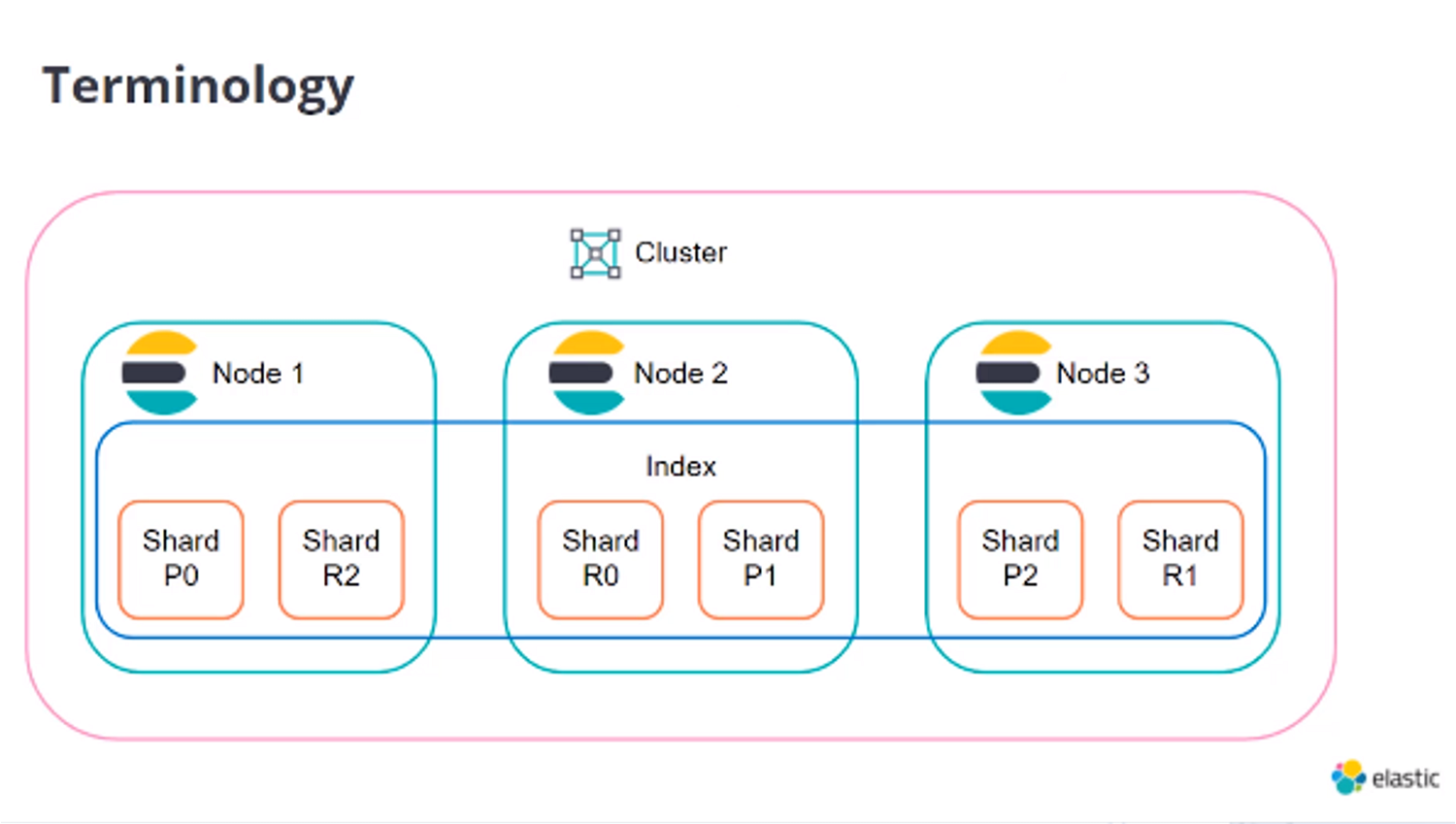
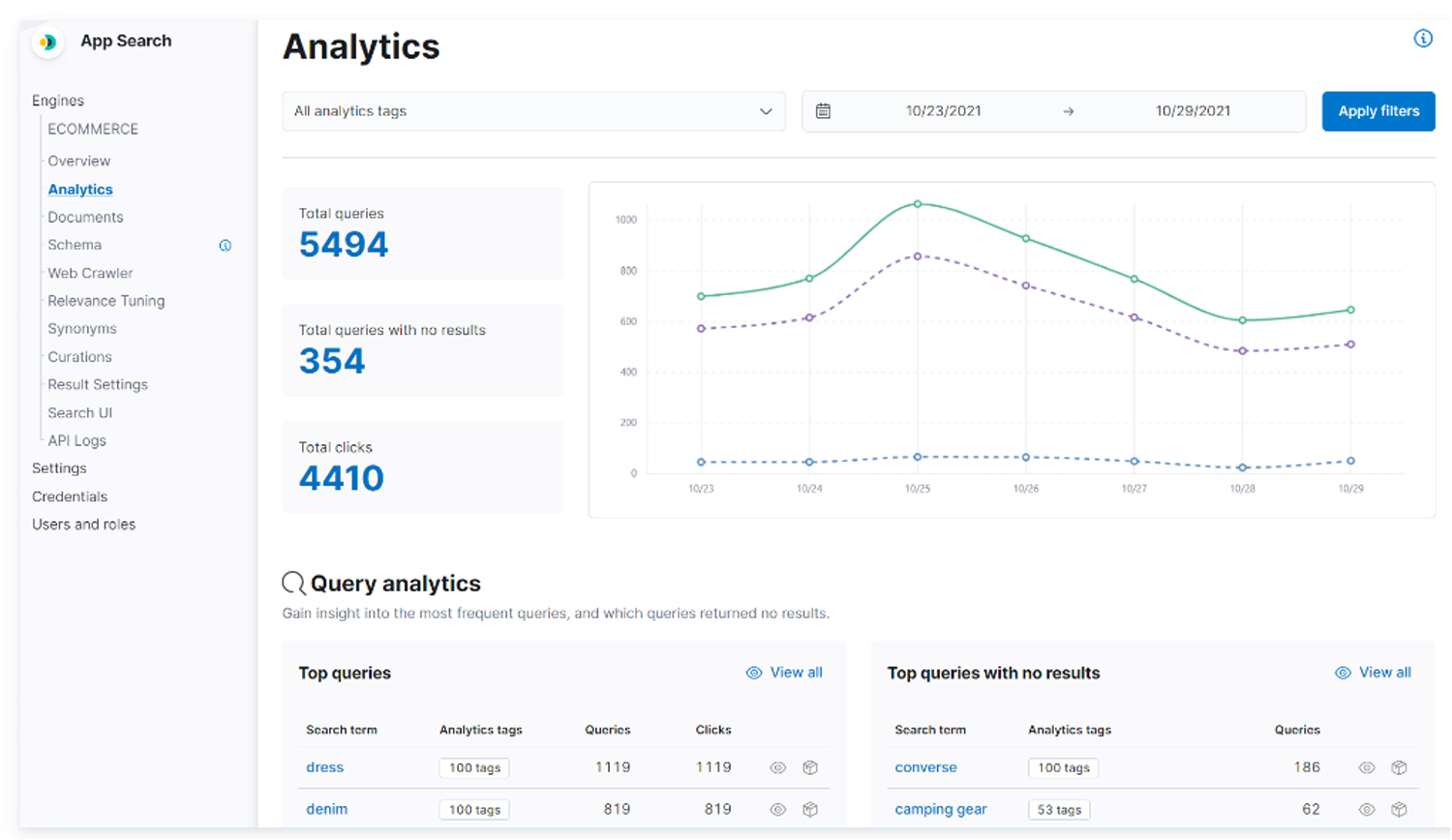
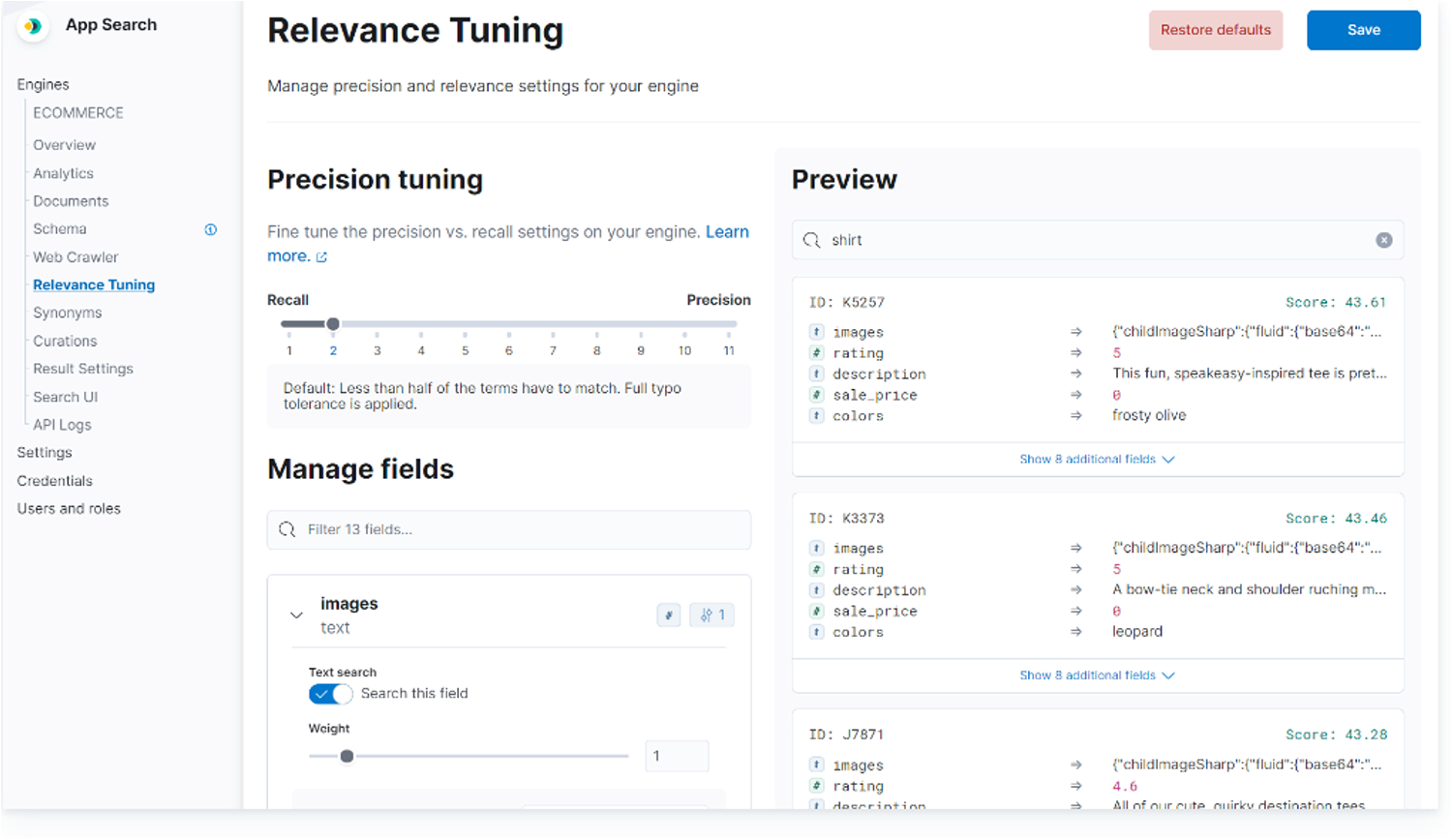
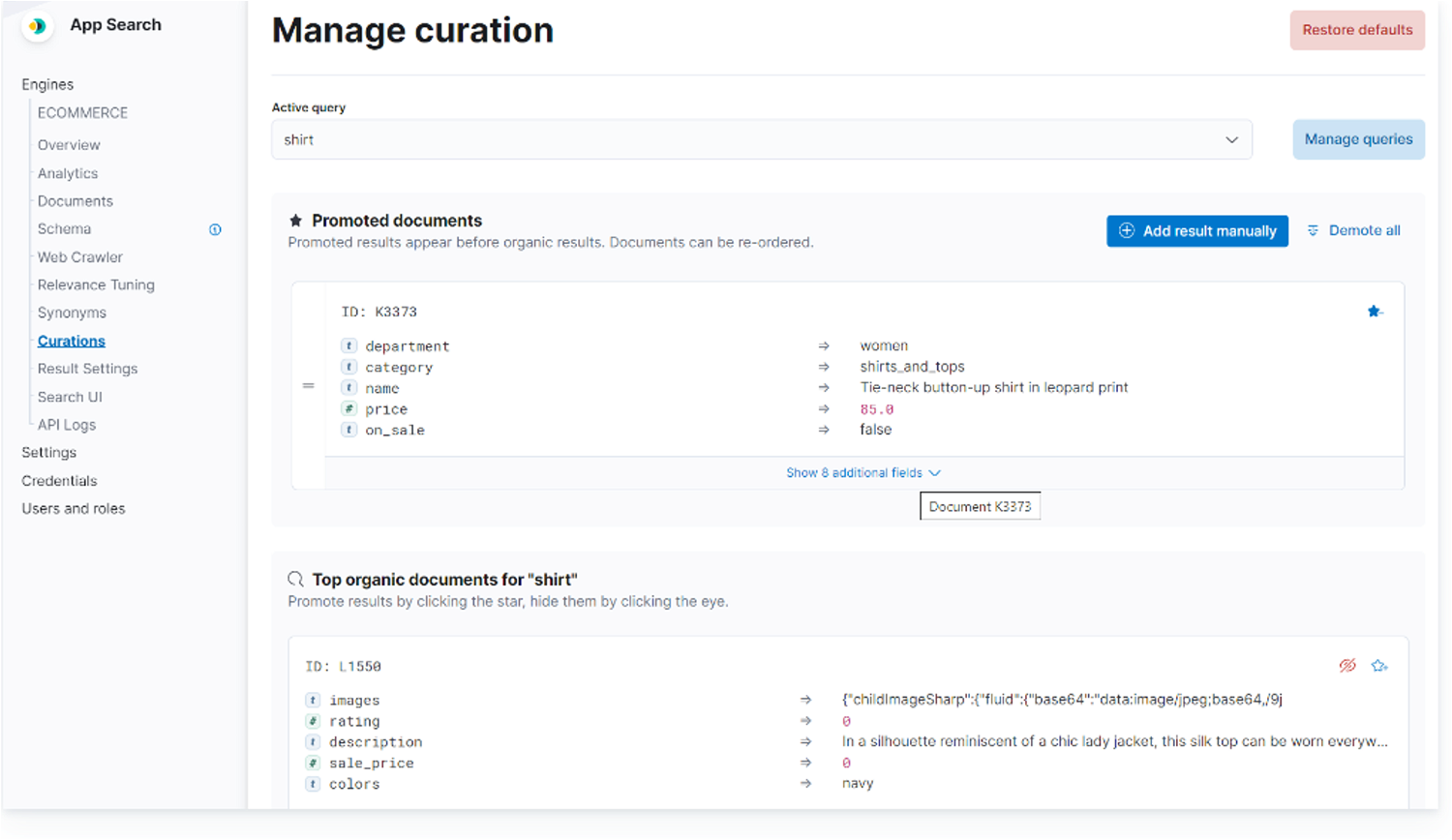
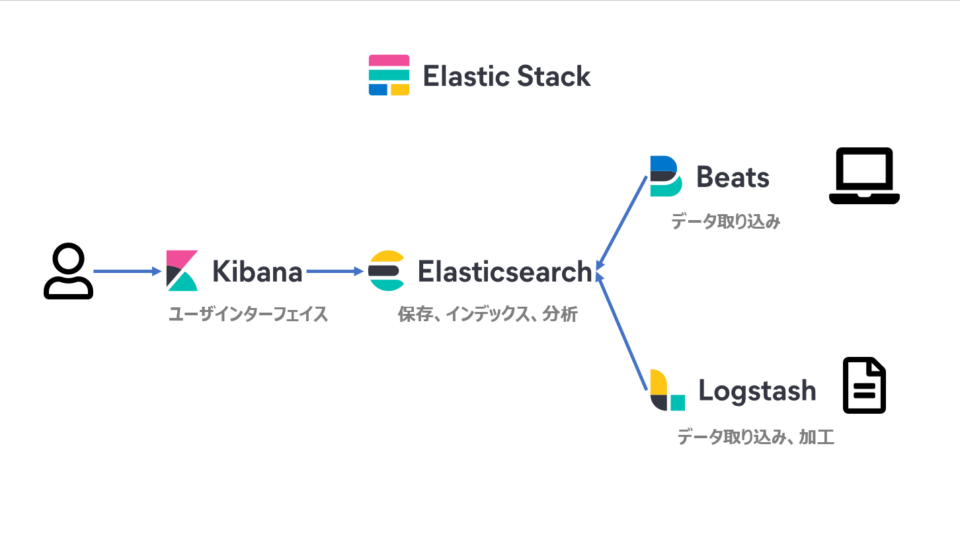
Elasticsearchは、オープンソースの分散検索/分析エンジンで、Apache Lucene を基盤として構築されています。大量のデータの高速な検索、関連性の細かな調整、検索の高度な分析などが可能になります。スキーマレスのJson形式でデータを追加し、RESTfulインターフェイスで検索します。通常版とElasticsearch Enterprise版があります。Enterprise版ではElastic App Searchというより高度な検索機能を使うことができます。その他に組織全体で様々なアプリケーションの検索ができるWorkplace Searchなどもあります。

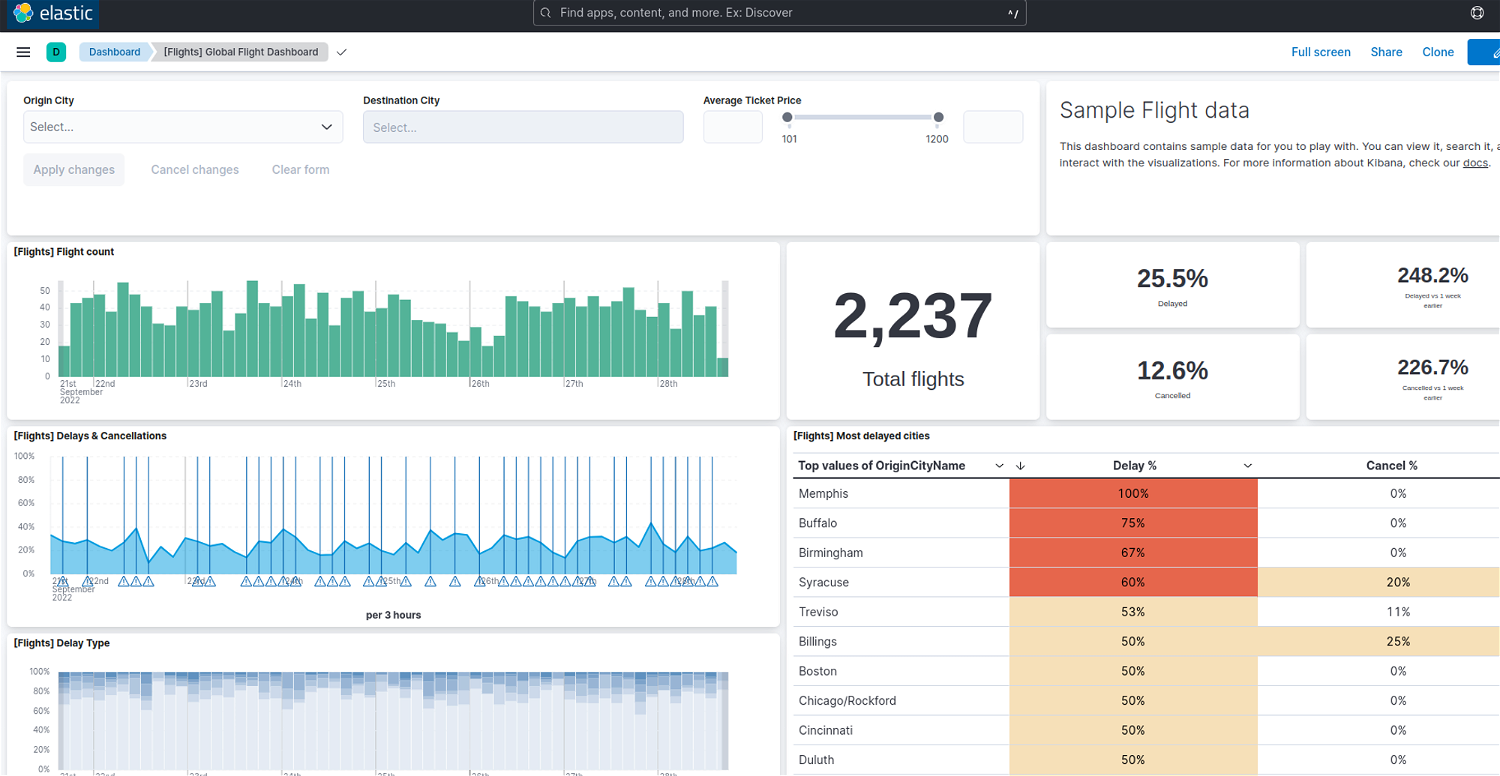
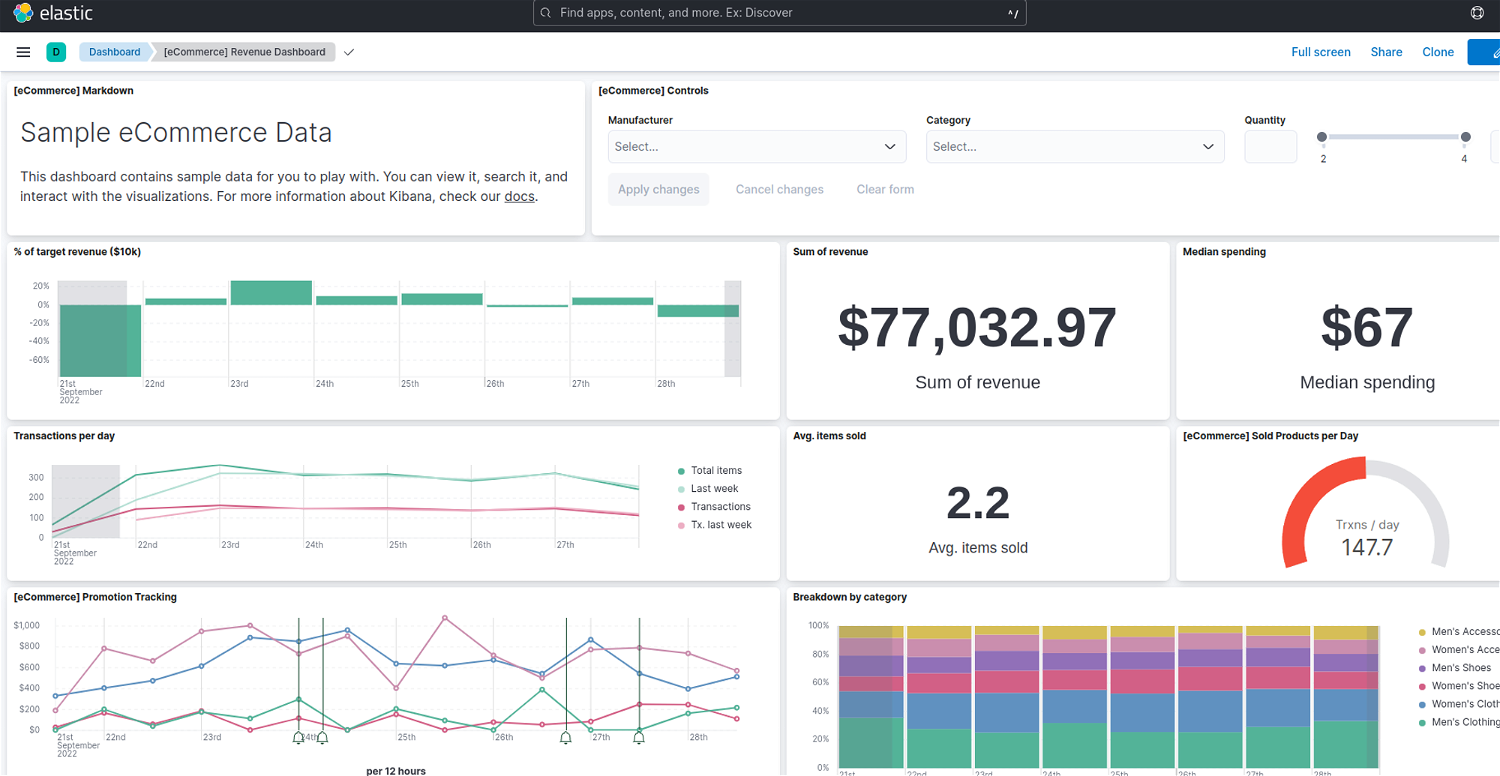
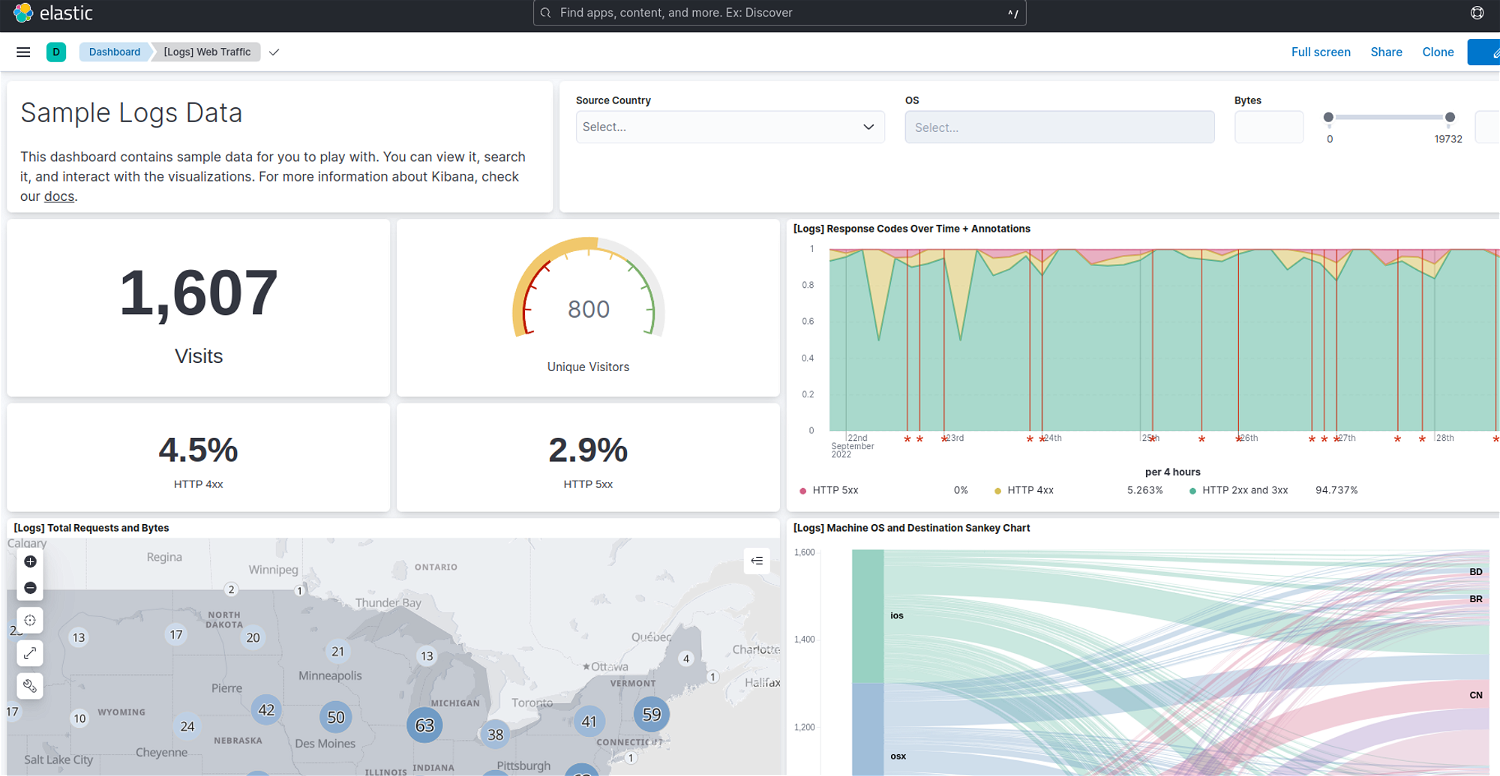
KibanaはElasticsearchの統合機能群であるElastic Stackのユーザーインターフェイスです。検索の分析、可視化、各アプリケーションとの連携、設定などができます。
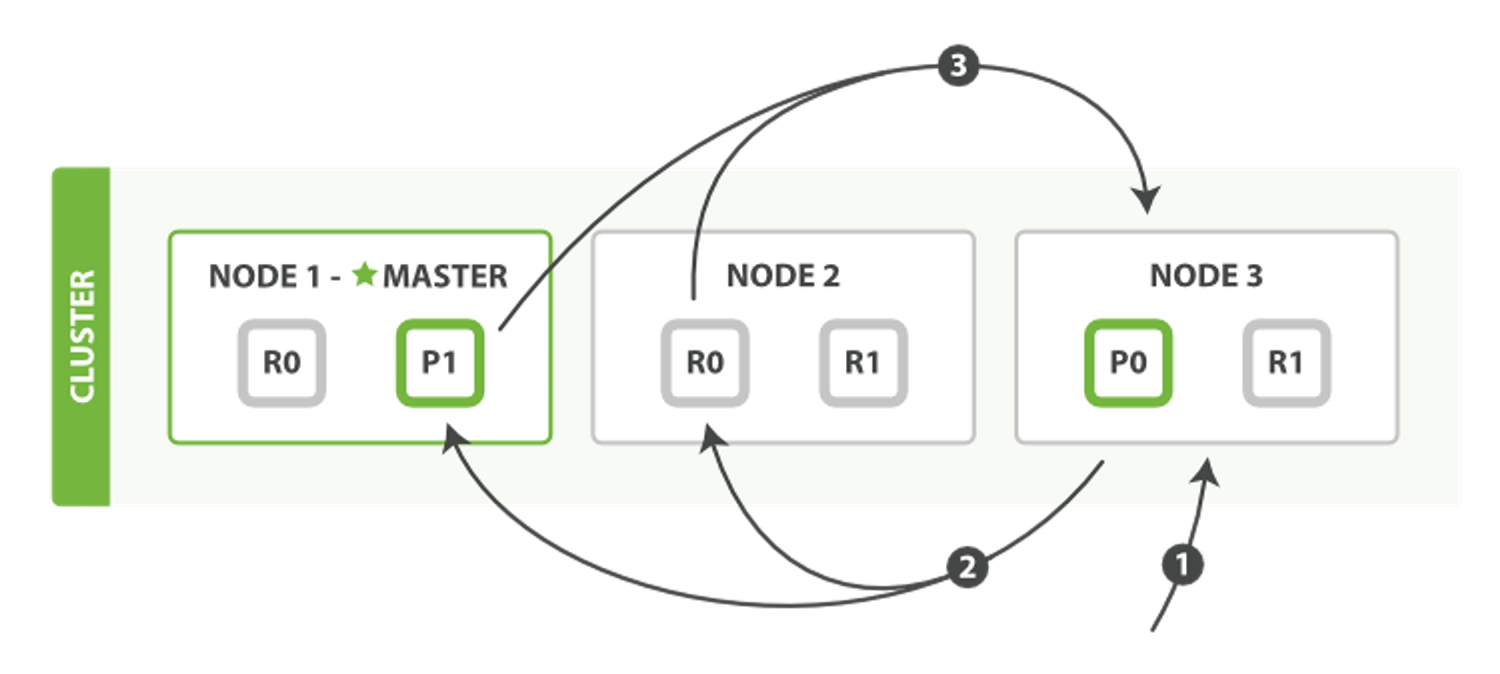
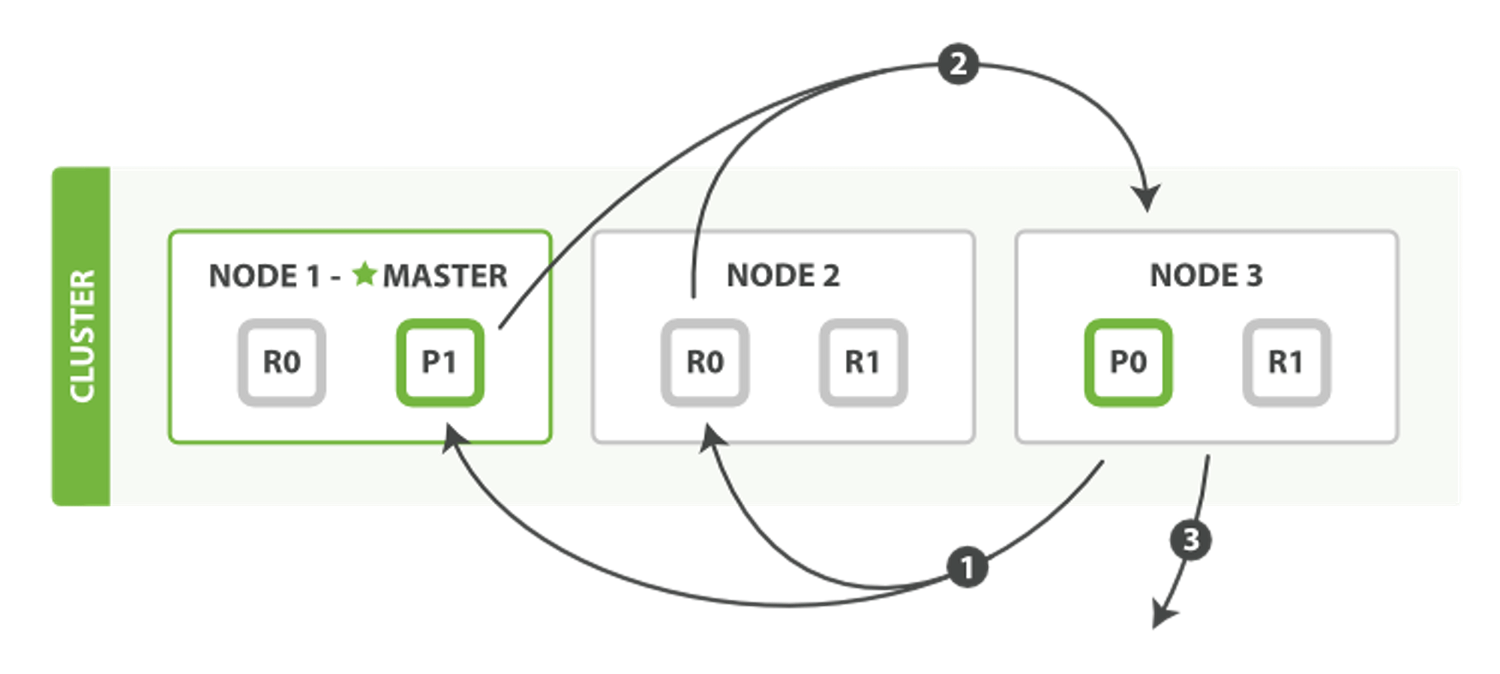
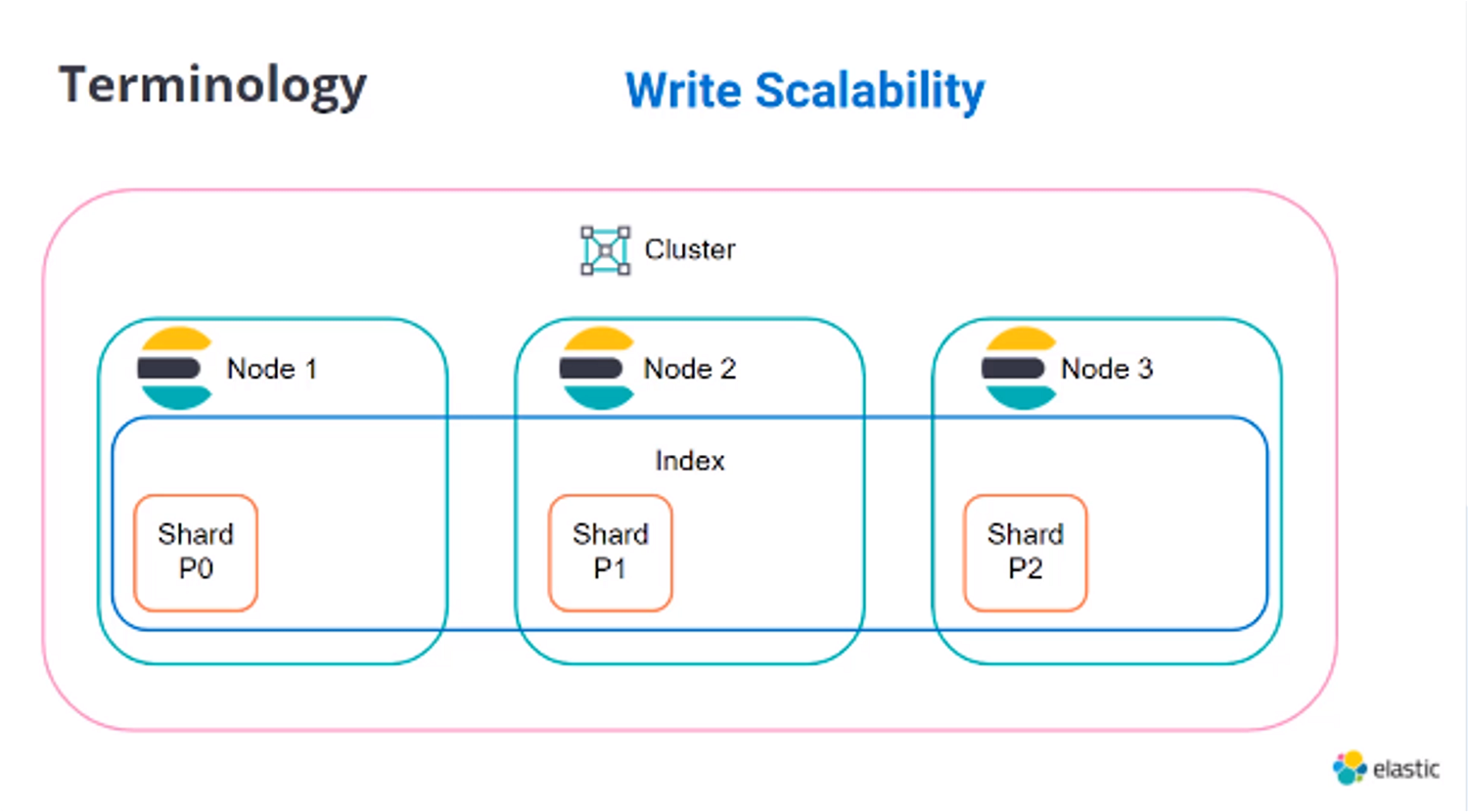
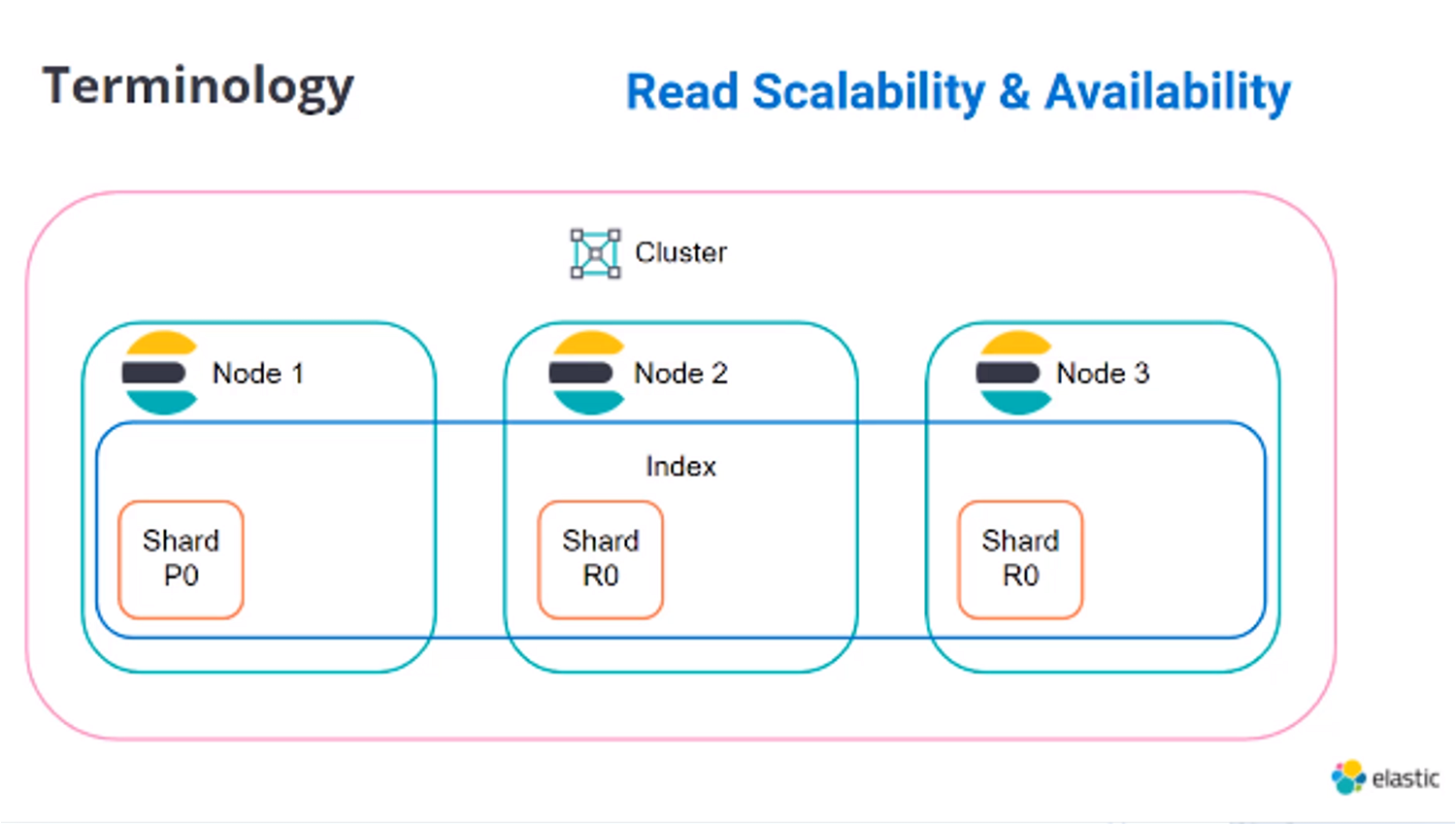
引用