Generalize for Future: Slow and Fast Trajectory Learning for CTR Prediction
2024/8/10 13:30 at 京都大学
AAAI論文読みLT会 株式会社スクラムサインx京都大学人工知能研究会 共催 発表資料
事前知識
CTR予測モデルの入力データは、多様な特徴量から構成されます。以下は、一般的な特徴量のカテゴリです:
- ユーザー特徴量:
- ユーザーID
- 年齢、性別、地域
- 過去のクリック履歴や購入履歴
- アイテム特徴量(広告特徴量):
- アイテムID
- アイテムのカテゴリや属性
- アイテムの価格
- コンテキスト特徴量:
- 時間(例:曜日、時間帯)
- デバイスの種類(例:モバイル、デスクトップ)
- ロケーション(例:都市、国)
- インタラクション特徴量:
- ユーザーとアイテムの過去のインタラクション(例:過去のクリック数)
- アイテムの表示回数
教師データ
- クリック クリックなし
論文モチベーション
- CTR予測モデルの学習を考察対象にしつつ、段階的な分布シフトを伴う時系列データへの対処の問題として枠組みを定式化。具体的には、概念ドリフトへのエンドツーエンドの適応のための新しいトレーニングフレームワーク、スロー&ファストトラジェクトリラーニング(SFTL)を提案しています。
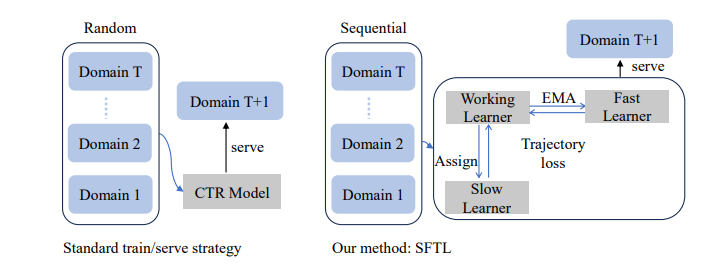
この方法は、時間を一定期間で区分している単位でドメインに対して、次の時間ドメインでの将来のパフォーマンスを最大化することを通して、メインの学習モデルのネットワークのロバストな特徴学習をまず行い、そこで得た学習パラメータから、ヒストリカルなパラメータ値の平滑化を行って、時系列的なものを考慮しているトラジェクトリネットワークの効率的な学習を実現しようとしています。
- 実験では、データセット全体をランダムにシャッフルする代わりに、逐次トレーニングを使用して時間的ドリフトに適応的に学習することを提案しています。さらに、提案手法の一般化ギャップの理論的理解を提供しまていますが、ここはあまり理解できていません。実世界のCTRデータセットを用いた実験から、SFTLフレームワークの有効性が示唆されています。
数式
通常のERM(Empirical risk minimization)の枠組み
過去の全てのデータを利用して学習し、Dt+1を予測しにいく
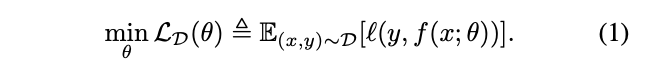
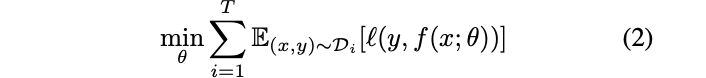
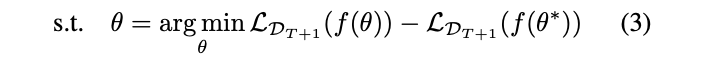

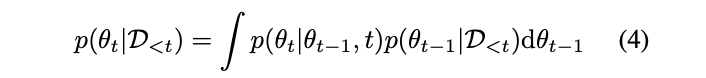

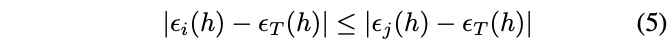
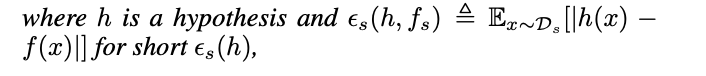
状態空間モデルでt-1時刻までのパラメータからt時刻のパラメータが生成されているとして
逐次的にもとめていくあり方
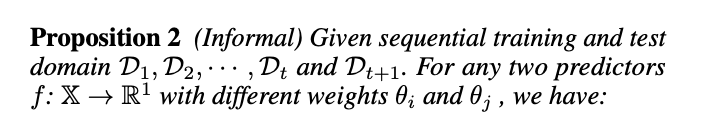
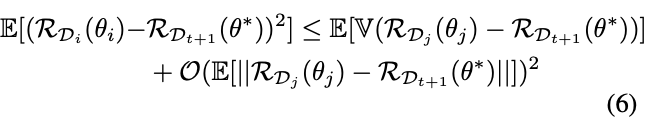
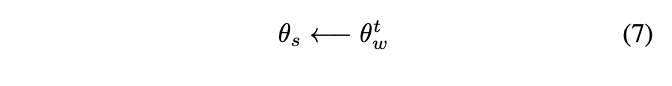

スロートラジェクトリーラーナーのパラメータは購買降下法で学習するワーキングラーナーのパラメータ重みの直接的な重み割りあてで更新しているが、アルゴリズムからわかるように結果として時間ドメインごとにスローラーナーは一時刻前におけるワーキングラーナーの重みパラメータを保持している
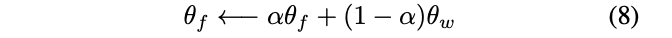

ファストラーナーの更新はαをハイパーパラメータとして調整しながら更新している
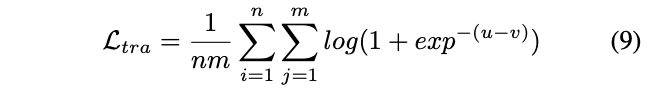
ワーキングラーナーの方が性能がよくなるようにロジスティック損失をとっている。
ロジスティック損失
0-1 損失では、「確実正解ではない」と「ぎりぎり正解」の両方は、同じペナルティを受ける。そこで、「確実正解ではない」の場合にはペナルティを大きく与え、「ぎりぎり正解」の場合にはペナルティを小さく与えるようにした損失関数が、ロジスティック損失となる。


ここはアペンディクスに詳しくあるようだが読めていない
下記の図が大枠の計算過程です。
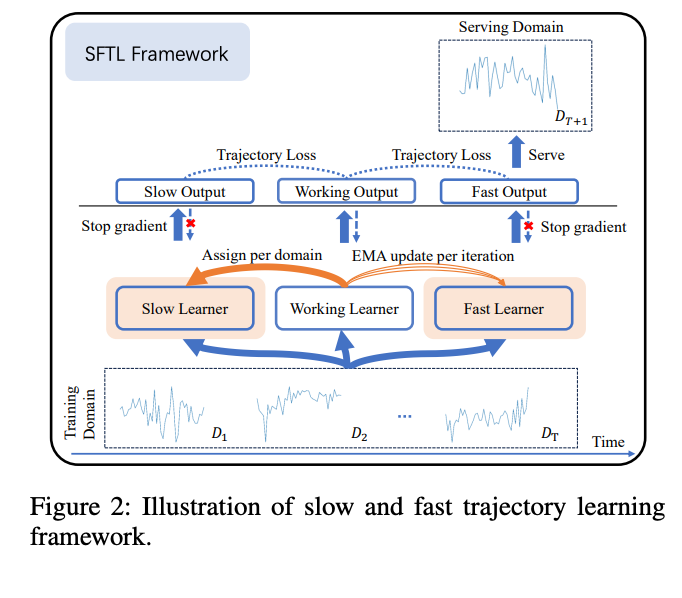
アルゴリズム
スタートは教師あり学習
その次の時間ドメインでトラジェクトリーロスを元にワーキングラーナー更新

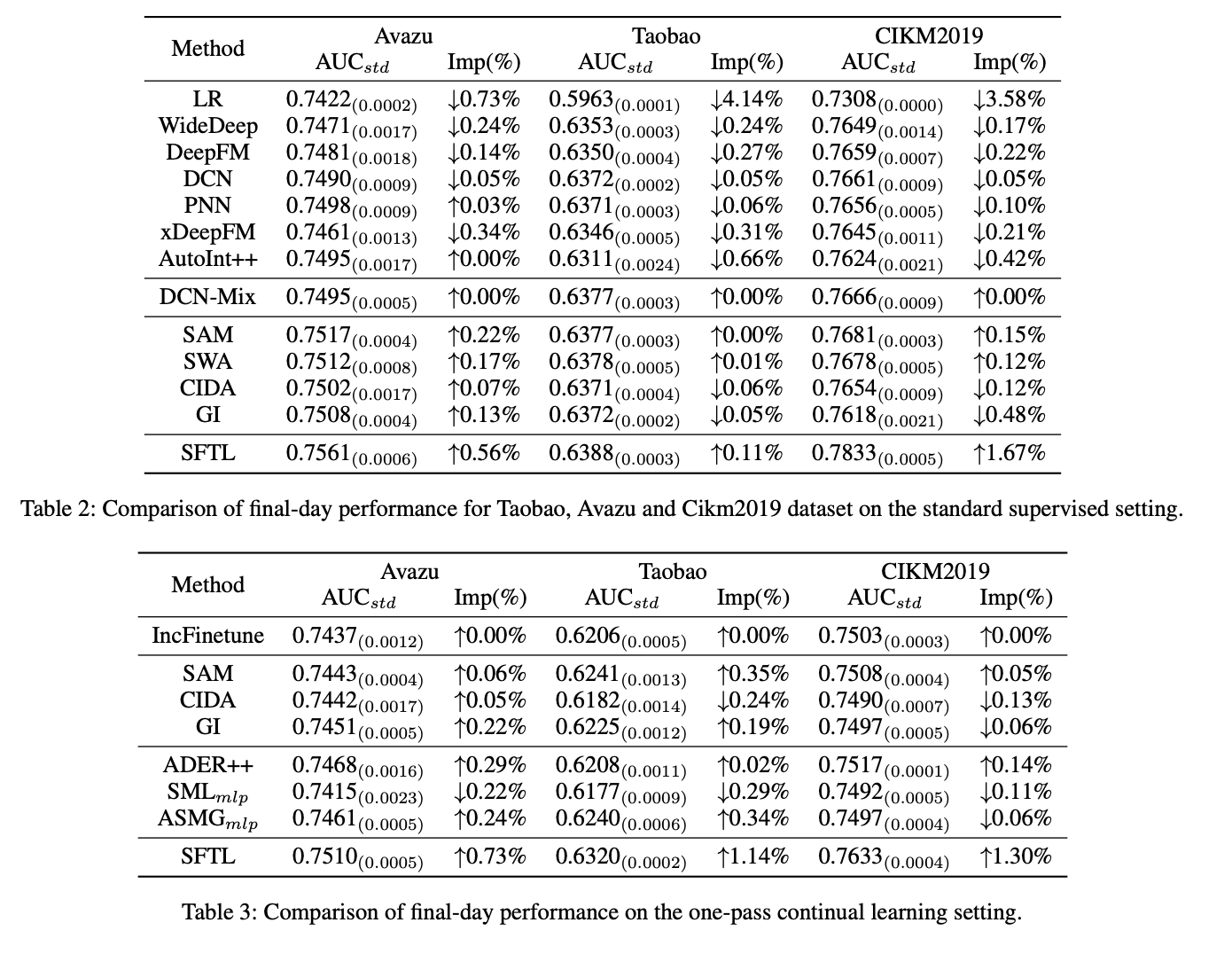
結果
ベースモデルと比較して全てのタスクでAUCが向上
まとめ
- 逐次学習して時間的なシーケンスの連続性を学習
- 時系列の特徴を学習するため Slow Learner Fast Learner Working Leanerの3つのモデルで学習しそれぞれ役割
- 学習はWorking Learnerのみで学習の高速化