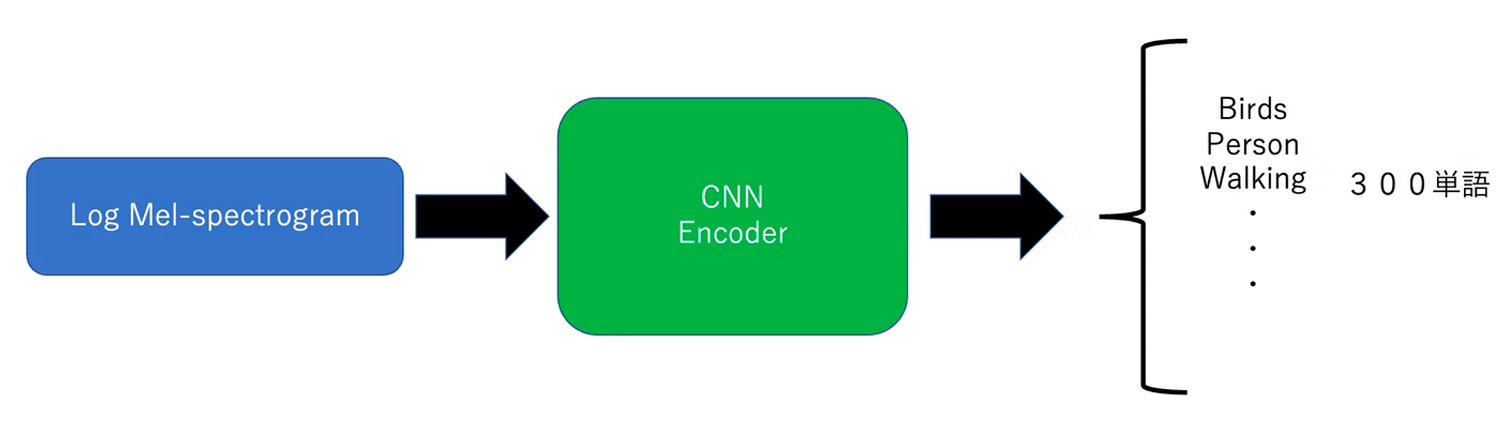
結果
以下が学習結果です。損失はバッチごとの損失の平均を計算しています。trainとtestとの損失の差が大きくなる結果となりました。
1epoch train mean loss : 5.226716177125947 test mean loss 7.841926097869873
10epoch train mean loss : 3.739801677718627 test mean loss 9.185269355773926
20epoch train mean loss : 3.2899816930294037 test mean loss 9.473353385925293
30epoch train mean loss : 2.999895176265092 test mean loss 9.60256290435791
40epoch train mean loss : 2.805177899588526 test mean loss 10.100188255310059
50epoch train mean loss : 2.6505848754823735 test mean loss 10.10529899597168
60epoch train mean loss : 2.565974382436381 test mean loss 10.014985084533691
70epoch train mean loss : 2.4416530115150774 test mean loss 10.202888488769531
80epoch train mean loss : 2.36368575573495 test mean loss 10.414170265197754
90epoch train mean loss : 2.3168762252394077 test mean loss 10.309037208557129
100epoch train mean loss : 2.336798207158536 test mean loss 10.409688949584961