Elasticsearchについて
社内技術勉強会 資料 2022年9月29日 19:00~20:00
作成者 Aoki Yuichiro
作成日 2022/9/29
更新日 2022/9/29

Elasticsearchは、オープンソースの分散検索/分析エンジンで、Apache Lucene を基盤として構築されています。大量のデータの高速な検索、関連性の細かな調整、検索の高度な分析などが可能になります。スキーマレスのJson形式でデータを追加し、RESTfulインターフェイスで検索します。通常版とElasticsearch Enterprise版があります。Enterprise版ではElastic App Searchというより高度な検索機能を使うことができます。その他に組織全体で様々なアプリケーションの検索ができるWorkplace Searchなどもあります。

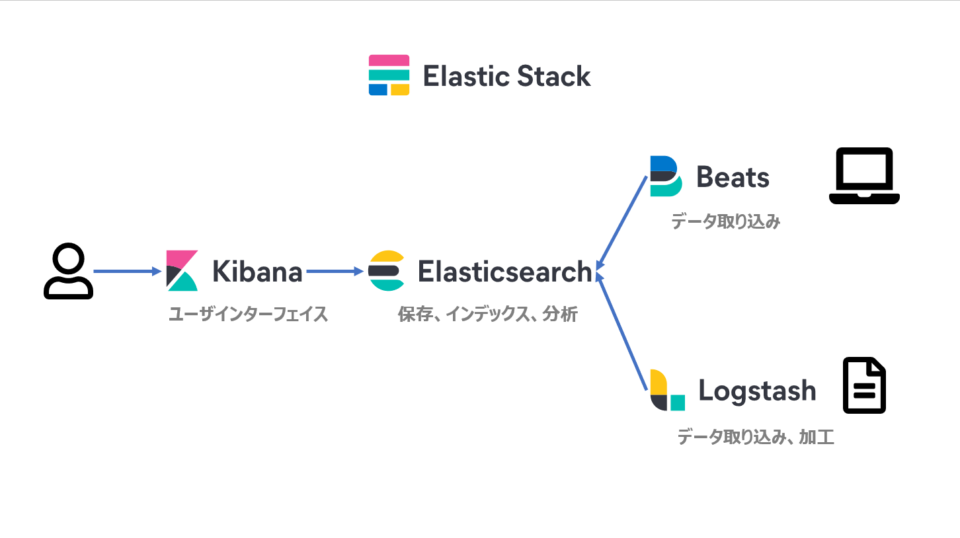
KibanaはElasticsearchの統合機能群であるElastic Stackのユーザーインターフェイスです。検索の分析、可視化、各アプリケーションとの連携、設定などができます。
引用
Apache Luceneとは
Javaで書かれたオープンソースの検索エンジンライブラリです。Elasticsearchの内部で使用されておりinverted indexという構成により高速でスケーラブルな検索を可能にしています。
Inverted Index
inverted indexを作成するにはドキュメントを ”term” または “token” と呼ばれる単語単位に分割し、並び替えたユニークなtermのリストを作成します。
例
- The quick brown fox jumped over the lazy dog
- Quick brown foxes leap over lazy dogs in summer
“quick brown” を検索する場合は以下のような結果になります。naive similarity algorithmを採用する場合は単語が出てくる数を数え、多い方がよりクエリに対して関連性があるとします。以下の例ではDoc_1のようがより関連性があることになります。
大文字小文字の区別の設定や関連する単語を設定することにより検索の精度を上げることができます。
参考
日本語での検索
デフォルトで日本語は一文字ずつ分割してinverted indexを作成してしまうため、Japanese (kuromoji) Analysis pluginをインストールしanalyzerをこちらを指定する必要があります。これにより日本語の単語ごとにインデックスが作成されます。
ディスクに書き込まれたinverted indexはイミュータブルです。これにより以下のメリットがあります。
- ロッキングする必要がない
- インデックスがkernelのファイルシステムキャッシュに読み込まれた場合、次からはディスクから読み込まずメモリから読み込むことができパフォーマンスが飛躍的に向上する
- その他のキャッシュ(フィルターキャッシュなど)がデータが変化しないため繰り返し使える
- ひとつのサイズの大きいinverted indexはデータが圧縮されるため、ディスクI/Oのコストを減らしたりインデックスをキャッシュするRAMを減らすことができる
分散検索の仕組み
Query Phase
query phaseでは送られたクエリはインデックス内のそれぞれのシャードに(primaryかreplica shard)に送られ、それぞれローカルで検索処理を実行しマッチするドキュメントの priority queue を作成します。priority queueの大きさはクエリのページネーションのパラメータによって決まり、例えば以下のように90番目から10件のドキュメントを検索する場合は100件のpriority queueを作成します。
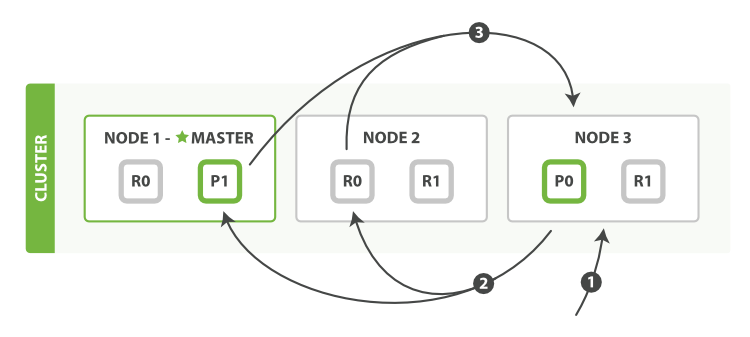
- クライエントからNode 3にクエリが届き、from, sizeのパラメータを元に空のpriority queueを作成
- Node 3がそれぞれのシェードのprimary shardかreplica shardへリクエストを送り、それぞれのシャードが検索をローカルで実行しfrom, sizeパラメータを元にpriority queueを作成
- それぞれのシャードがドキュメントID、並び替えの値が入ったpriority queueをNode 3に返し、Node 3がそれらをまとめ並び替えの処理を行う
Fetch Phase
fetch phaseではマッチしたドキュメントを取得します。
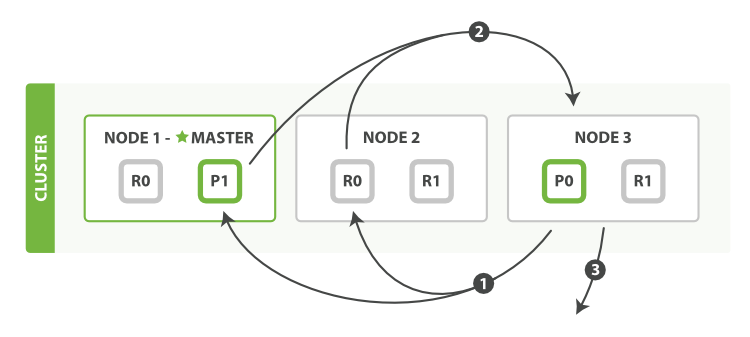
- coordinating node(リクエストを送られたノード、上記ではNode 3)がどのドキュメントを取得するか判断し、それらに関係するシャードに複数回GETリクエストを送信
- それぞれのシャードがドキュメントをcoordinating nodeに返す
- 全てのドキュメントが取得できた後、coordinating nodeがクライエントに結果を返す
特徴
拡張性
クラスタ構成で拡張でき、データの冗長化や安定的な運用ができます。以下のようにシャーディングによってインデックスの読み書きのパフォーマンスを高速にします。それぞれのシャードがLuceneインデックスのインスタンスとなっており、データをインデックス化しクエリを一部処理します。
Cluster: ノードの集合体
Node: Elasticsearchのインスタンス
Index: クラスタ内でシャードで構成されるドキュメントのコンテナ
Shard: Luceneインデックスのインスタンス、primary shards, バックアップのためのreplica shardsなどがある
Document: インデックスに属するJson形式のデータ
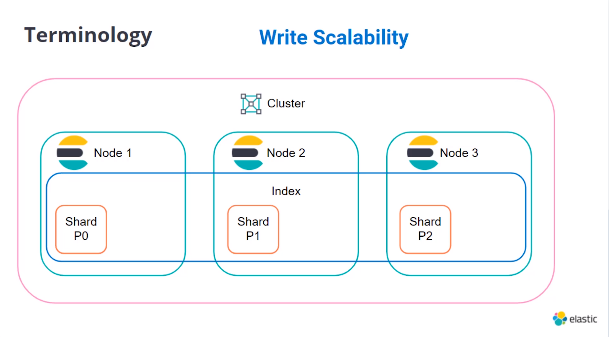
各ノードのコア、スレッドを使用し並列でデータをシャードに追加できる
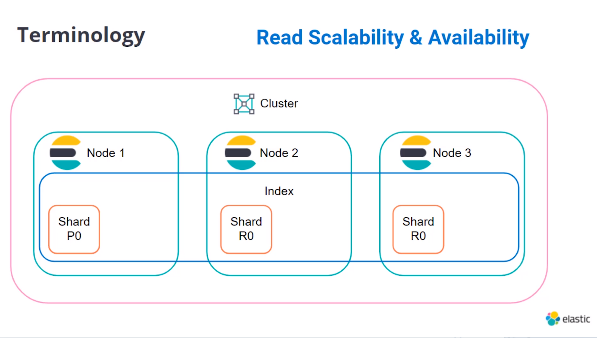
上記のように分散して検索ができ、一つのノードが落ちた場合でもreplica shardによりデータが失われないようになっている
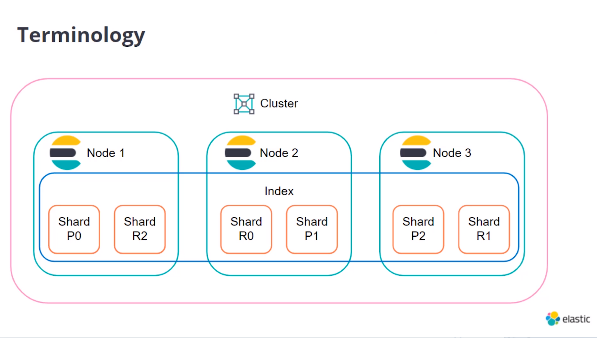
構成例
追加したドキュメントがニアリアルタイムで検索可能
新しく追加したドキュメントはほぼリアルタイム(1秒以内)で検索可能となります。
k-nearest neighbor (kNN)
ドキュメントにベクトルを追加することでk-nearest neighbor (kNN)検索が可能です。以下の2つの方法でkNN検索ができます。
Exact kNN
全探索するため精度は確かですが、大きいデータセットではうまくスケールしません。検索結果の数を制限したり、条件で絞り込みすることでパフォーマンスが向上します。
Approximate kNN
インデックスの時間がかかることと精度が完璧でないという点と引き換えに高速な探索が可能です。現時点では(2022/9/28)プレビュー段階のため仕様が変更になったり削除される可能性もあります。クエリで指定するnum_candidatesを増やすと、精度が上がる代わりに探索により時間がかかります。HNSW algorithm を採用しており他のkNN探索アルゴリズムと同様に精度を犠牲にして探索時間を高速にしているため必ずしも結果が正しいとは限りません。
文字一致と併用して検索することができ、その際は重み(boost)を加え結果を調整します。
例 "mountain lake" というワードと [54, 10, -2] というimage-vectorでクエリ
boostが重みとなり上記のような重みを掛け合わせた合計がscoreとなり、この順に結果を返します。
高度な分析、可視化ツール
ElasticsearchのユーザーインターフェイスであるKibanaはElasticsearchへインポートされたデータの可視化を簡単することができます。また検索のみならず、データ取り込みのプラットフォームであるBeatsやデータ処理のパイプラインであるLogstashを用いてサーバーのログ、売上状況など様々なデータを可視化する用途としても使われています。
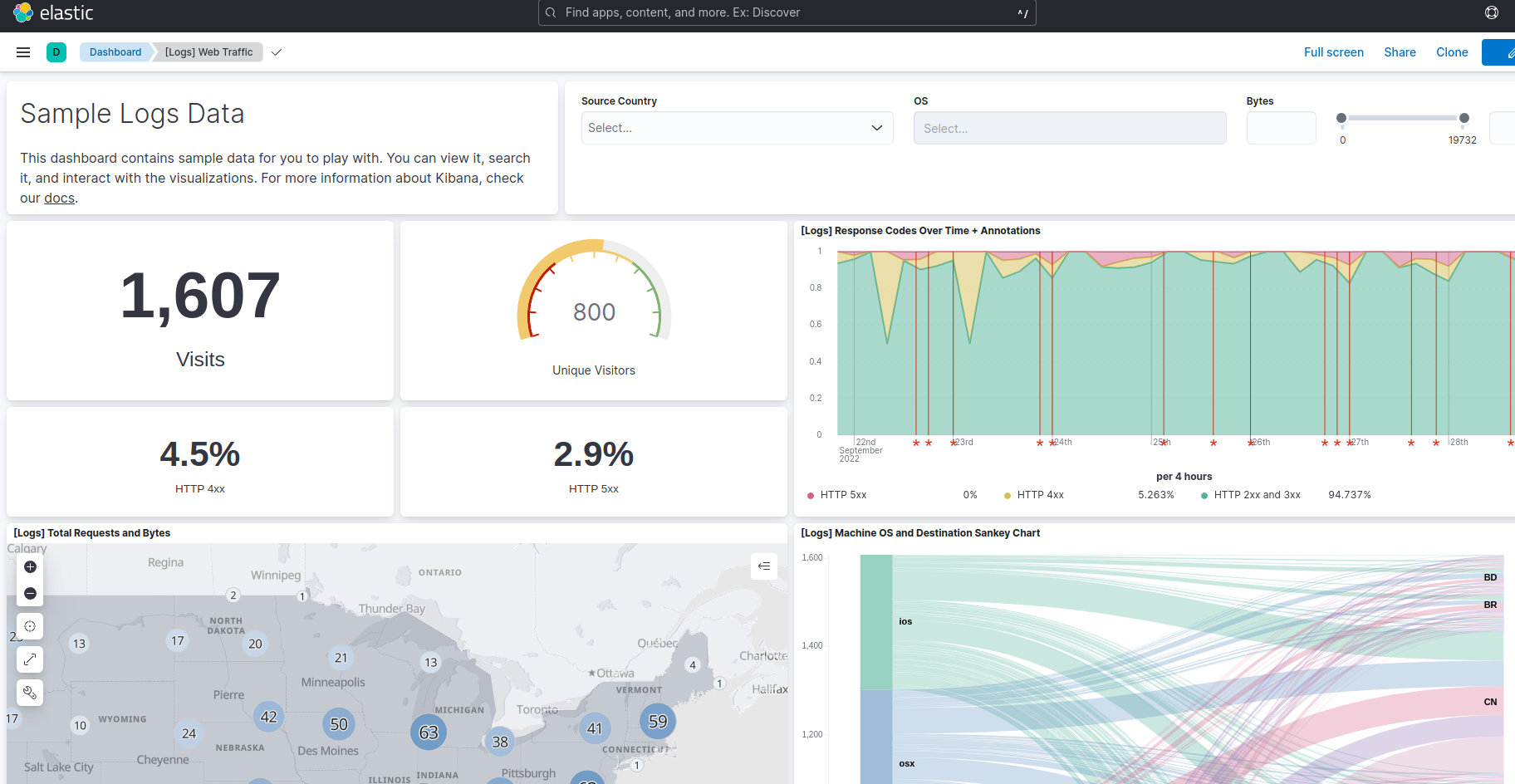
App Search
Elastic Enterprise版ではより高度な検索機能を備えたApp Searchを使うことができます。
検索クエリの分析
検索されたワードや件数などの分析を行うことができます。
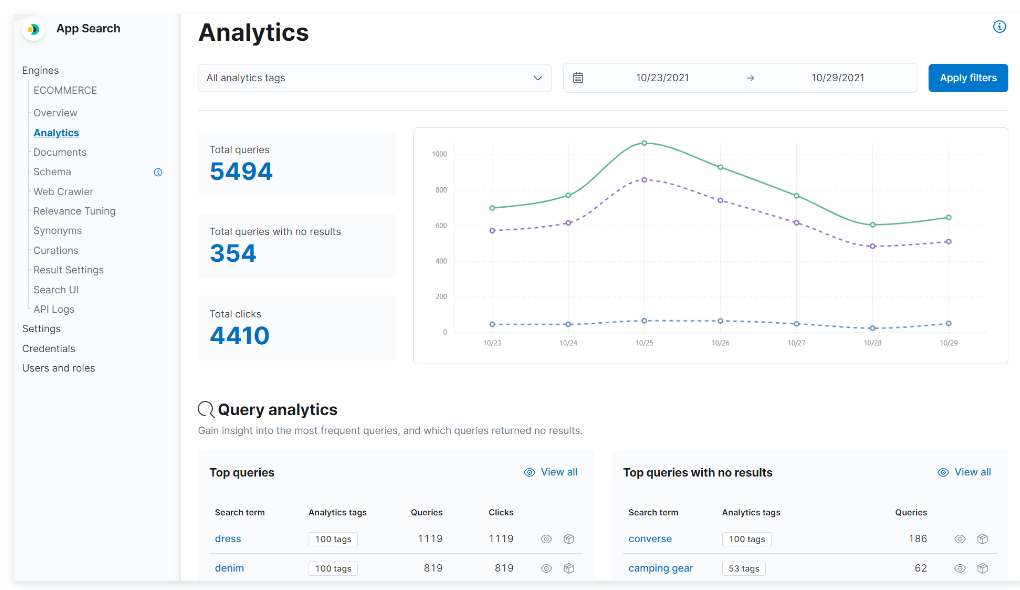
検索の関連性のチューニング
重みのチューニングの設定ができます。
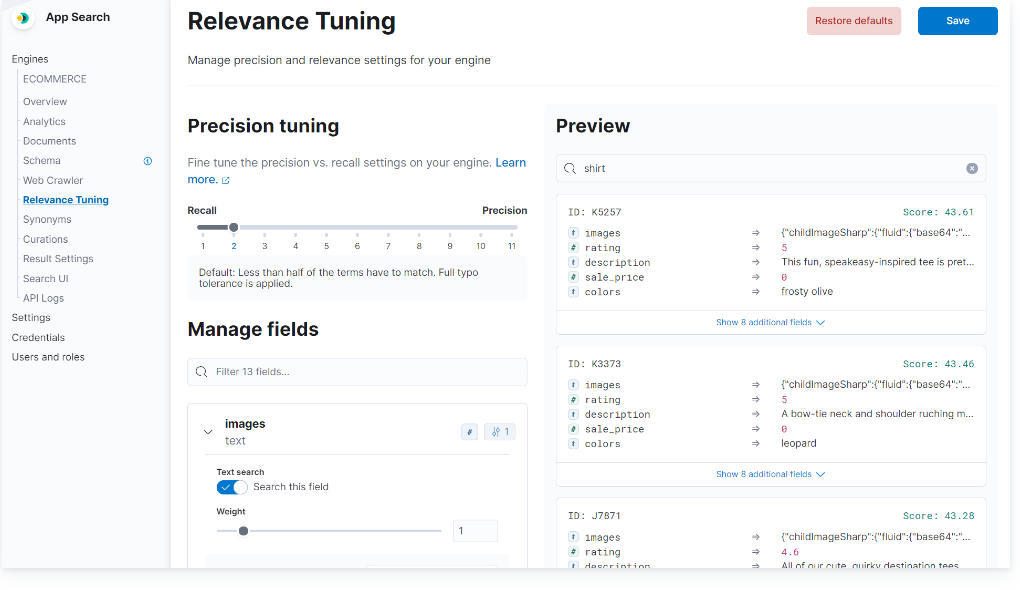
キュレーション
ある検索ワードに対して上位に結果を返すドキュメントや反対に結果から隠すドキュメントを設定することができます。
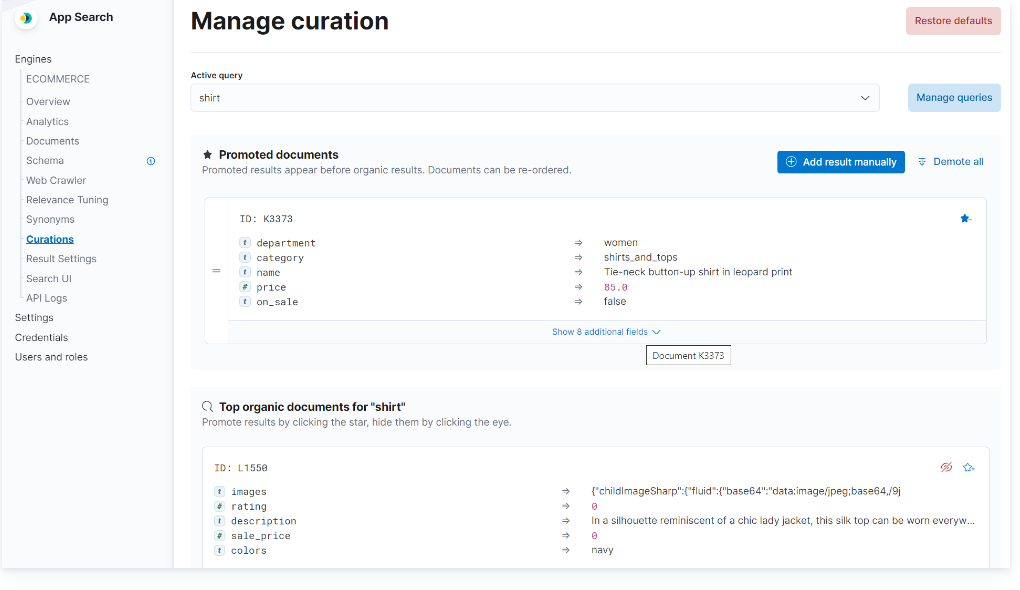
同義語
同義語を登録することでその同義語でもマッチした検索結果を返すようになります。
UIのインターフェイス
オープンソースのSearch UIというReactのコンポーネントが用意されており、こちらを用いて簡単にReactのアプリケーションに検索のUIを取り込むことができます。App Searchのコンポーネントとプレビュー段階の通常版のコンポーネントがあります。タイプするごとに検索されるsearch-as-you-type機能、入力予測、条件絞り込みのチェックボックス、ページネーション、検索されたワードのハイライトなどの機能があります。
MongoDBのデータを同期
Goで書かれたオープンソースのMonstacheを使い、MongoDBのデータをElasticsearchへインポートすることができます。その際にMonstacheはMongoDBが発するイベントログのOplogでElasticsearchと同期するため、MongoDBをreplica setでデプロイする必要があります。
参考